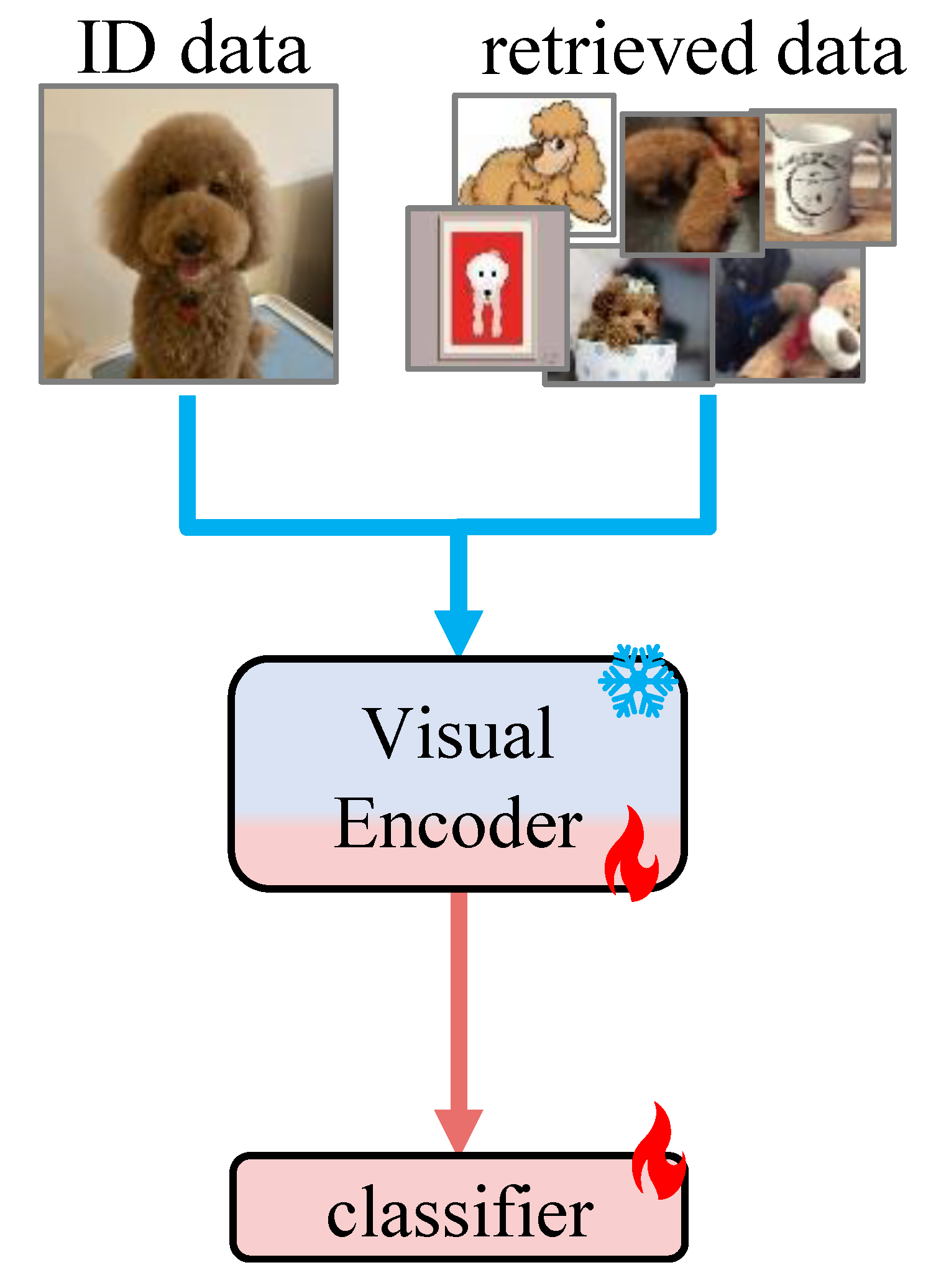
We present a validation strategy based on ''performance gains'' on the ID training data and the retrieved data.
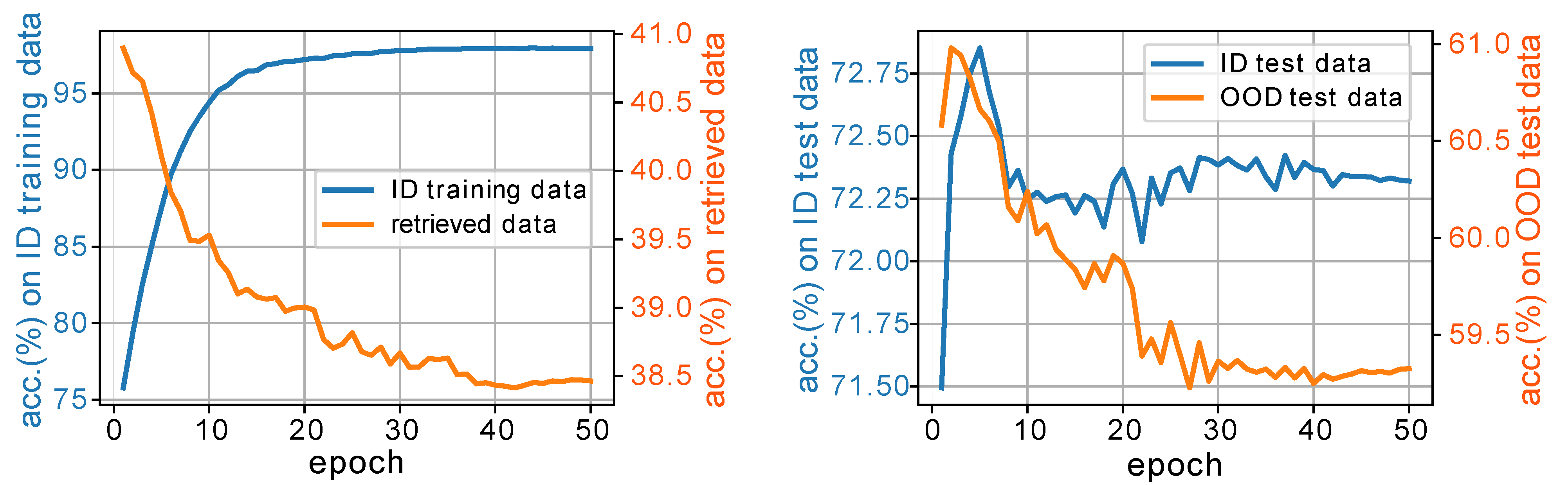
Specifically, for each checkpoint, say at epoch-\(i\), we calculate its training accuracy (\(\text{acc}^i_{ID}\)) and the accuracy on the retrieved data (\(\text{acc}^i_{RT}\)).
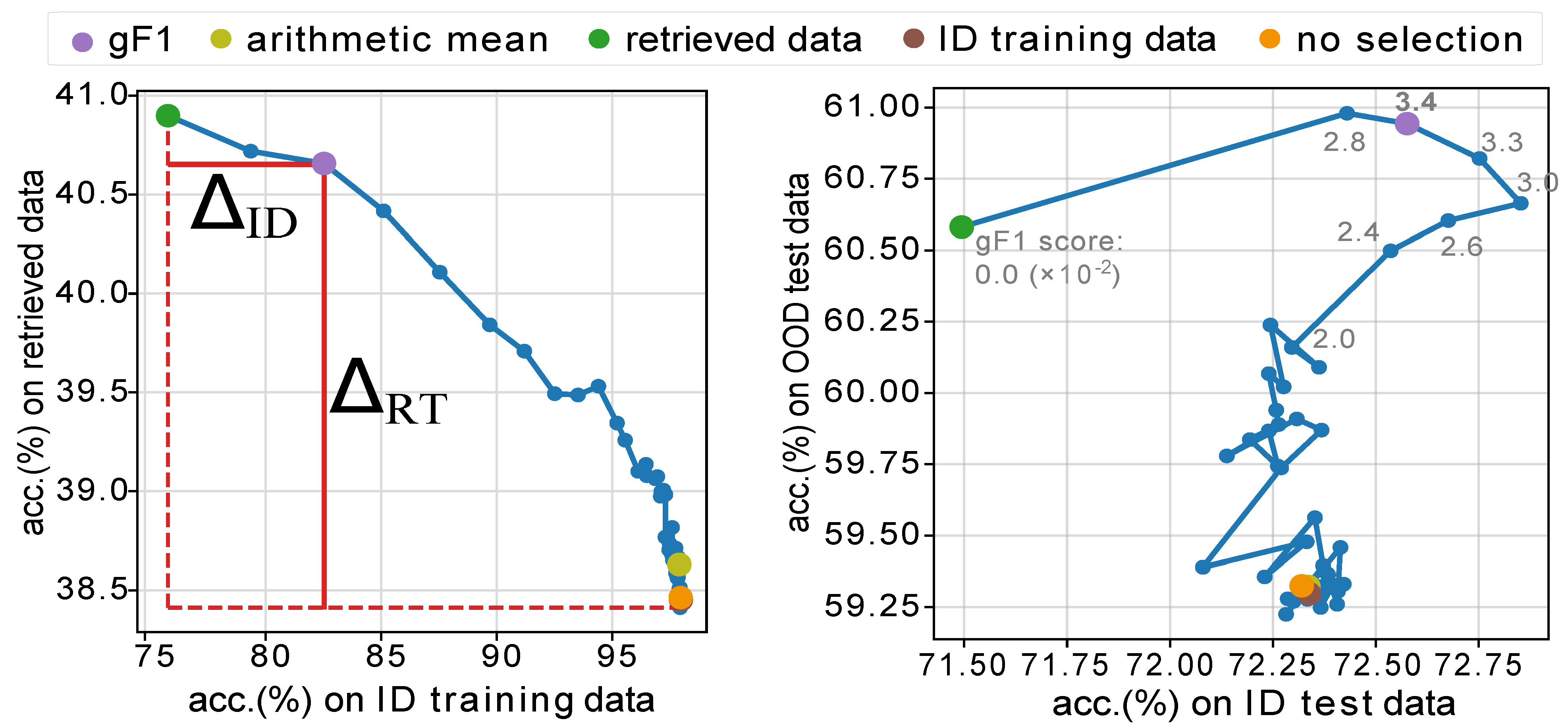
We place all the checkpoints on a 2D plane with \(x\) and \(y\) specifying the two accuracies.
Then, for the \(t^{th}\) checkpoint,
we compute its ''performance gains'' on the ID training data as \(\Delta_{ID}^t= \text{acc}^t_{ID} - \min_i(\text{acc}^i_{ID})\),
and on the retrieved data as \(\Delta_{RT}^t=\text{acc}^t_{RT}-\min_i(\text{acc}^i_{RT})\).
We measure the generalization ability of this checkpoint using their harmonic mean (in spirit of F1 score),
dubbed gF1:
\begin{equation}
\text{gF1}^t = 2 \times \frac{\Delta_{ID}^t \times \Delta_{RT}^t}{\Delta_{ID}^t + \Delta_{RT}^t}.
\end{equation}
gF1 enables checkpoint selection
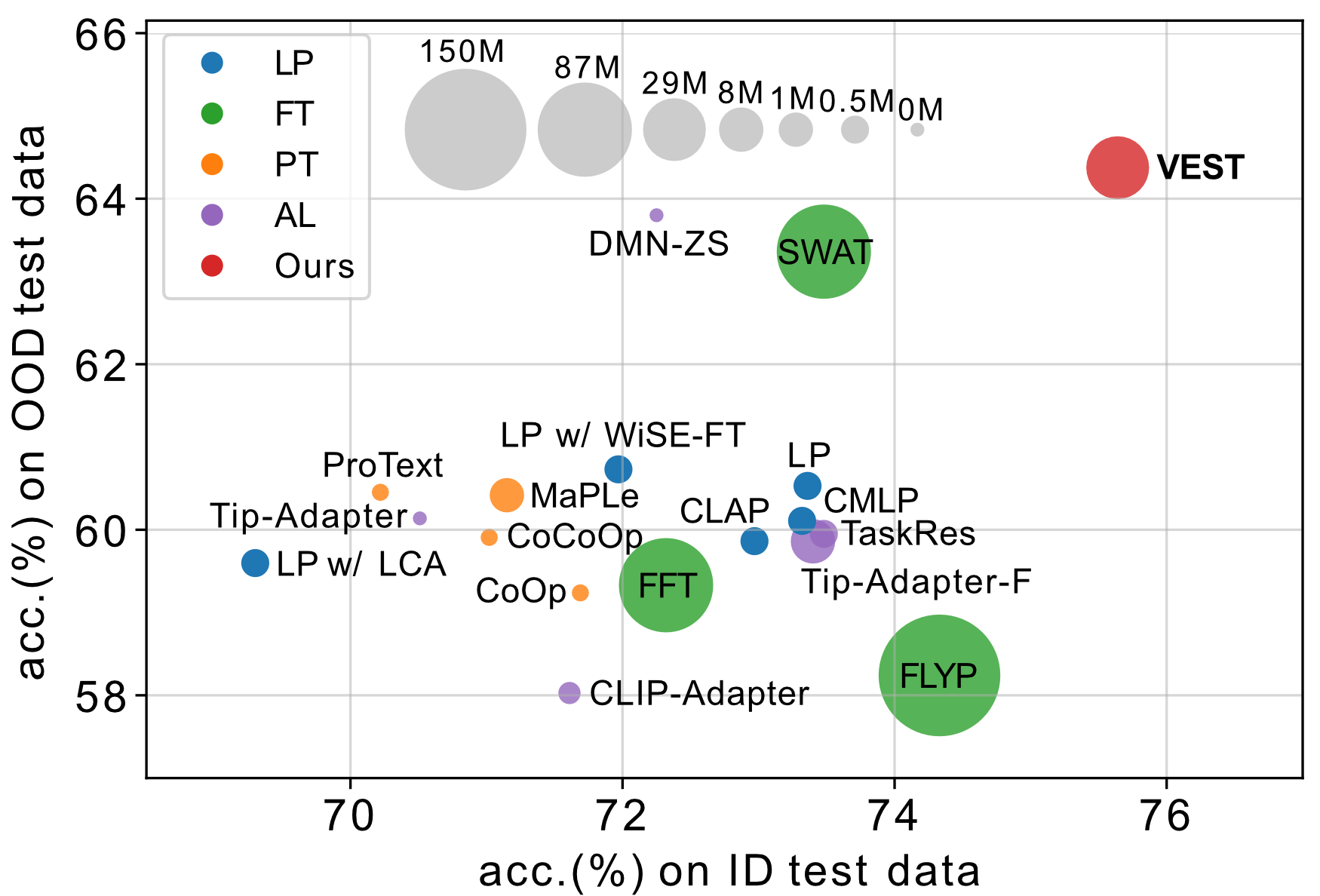
Our validation strategy selects the checkpoint at epoch-3 after fully finetuning the VLM.
We verify this selection by comparing these checkpoints w.r.t accuracies on the OOD and ID test data.
Results show that the selected checkpoint does generalize robustly well to the test data.
gF1 enables layer selection
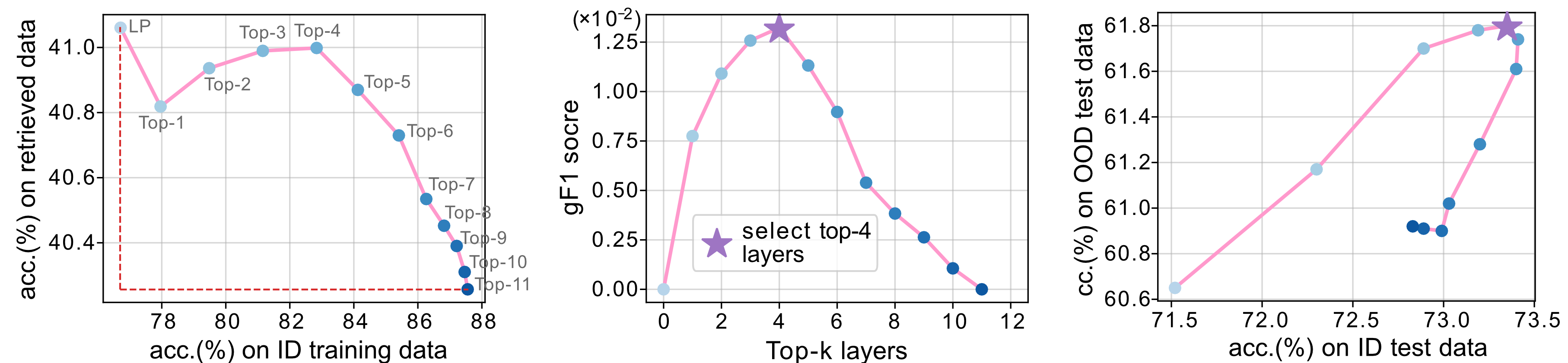
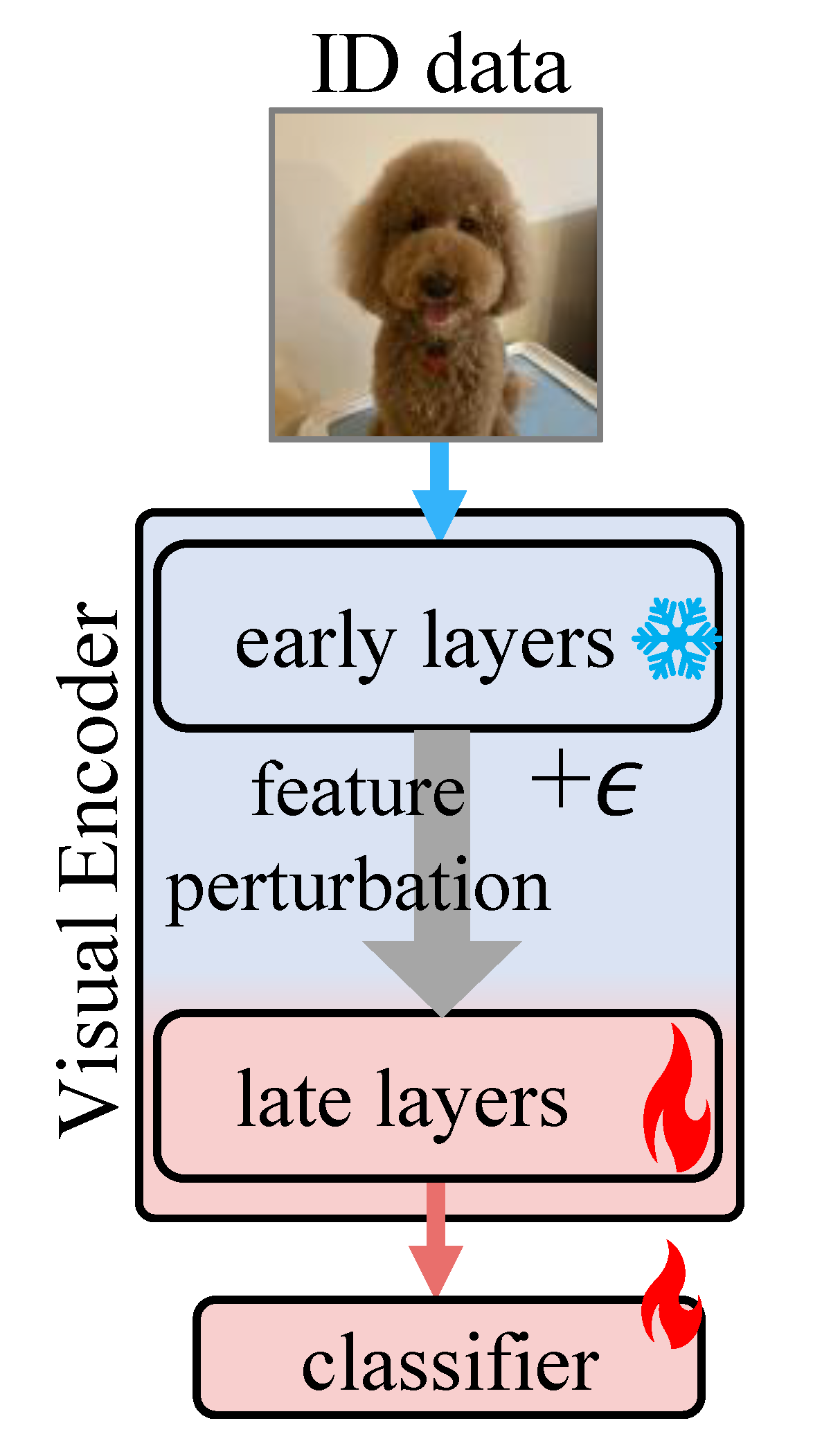
We extend our validation strategy to decide how many top layers to partially finetune (PFT) in a Transformer.
In practice, it selects the top-4 layers.
The resulting checkpoint accuracies for different \(k\) on the ID and OOD test sets demonstrat that
our validation strategy effectively determines the top-\(k\) layers to PFT for better robustness and generalization.